
Formenti Nicolò– rev.1.0 – https://creativecommons.org/licenses/by-nc-sa/3.0/
 La conservazione dei siti Web è una attività che ebbe inizio congiuntamente con la diffusione del World Wide Web al vasto pubblico (avvento dell’HTML); di fatto già dalla metà degli anni novanta nacquero iniziative volte a preservare questo nuovo patrimonio digitale, in particolare nel 1996 venne fondata da Brewster Kahle la “Internet Archive”, una biblioteca digitale non profit con lo scopo dichiarato di consentire un “accesso universale alla conoscenza”. In quegli anni viene coniato il termine “Web Archiving”, come il processo di collezionare parti significative del web per assicurare che le informazioni siano preservate in un archivio a lungo termine per futuri ricercatori, storici, sociologi ed in generale per il pubblico di domani. Dall’evoluzione dell’esperienza dell’ Internet Archive e con il contributo di diverse biblioteche nazionali ed università, nacque nel 2003 l’ International Internet Preservation Consortium (IIPC).
La conservazione dei siti Web è una attività che ebbe inizio congiuntamente con la diffusione del World Wide Web al vasto pubblico (avvento dell’HTML); di fatto già dalla metà degli anni novanta nacquero iniziative volte a preservare questo nuovo patrimonio digitale, in particolare nel 1996 venne fondata da Brewster Kahle la “Internet Archive”, una biblioteca digitale non profit con lo scopo dichiarato di consentire un “accesso universale alla conoscenza”. In quegli anni viene coniato il termine “Web Archiving”, come il processo di collezionare parti significative del web per assicurare che le informazioni siano preservate in un archivio a lungo termine per futuri ricercatori, storici, sociologi ed in generale per il pubblico di domani. Dall’evoluzione dell’esperienza dell’ Internet Archive e con il contributo di diverse biblioteche nazionali ed università, nacque nel 2003 l’ International Internet Preservation Consortium (IIPC).-
Consentire la raccolta, la conservazione e l’accesso a lungo termine di un ricco corpo di contenuti Internet da tutto il mondo.
-
Favorire lo sviluppo e l’uso di strumenti comuni , le tecniche e gli standard per la creazione di archivi internazionali.
-
Essere un forte sostenitore internazionale per le iniziative e la legislazione che incoraggiano la raccolta , la conservazione e l’accesso ai contenuti Internet .
-
Incoraggiare e sostenere le biblioteche , archivi, musei e istituzioni culturali in tutto il mondo per affrontare i contenuti di raccolta e la conservazione di Internet .
Le fasi del Web Archiving
Selection : La scelta delle risorse web che vanno conservate e la frequenza con cui viene operata tale conservazione.
Harvest : La raccolta vera e propria delle informazioni sul web selezionate al punto precedente.
Preservation : La conservazione a lungo termine delle risorse raccolte
Access : La garanzia di poter accedere alla risorsa conservata a lungo termine in futuro
Sono le priorità fondamentali di oggi per poter assicurare il mantenimento delle informazioni di oggi nel futuro. L’archiviazione del Web, sposta negli step più a valle, il compito di esaminare le risorse, organizzarle, determinarne chiavi di ricerca, indici fulltext ed estrazione di metadati e correlazioni automatiche. Questa attività, che è il fulcro del successo della consultazione dei documenti nei tradizionali processi ‘controllati’ di archivistica, viene effettuata e pianificata già nelle primissime fasi di gestione della risorsa, ovvero, prima che la risorsa web venga decontestualizzata dal suo ambito. Questa sarà una considerazione fondamentale, per portare alla costruzione di risorse web con gli stessi criteri che adottiamo quando formiamo documenti digitali atti alla conservazione a lungo termine; proprio perché tali vogliamo che siano, almeno per quanto riguarda il sottoinsieme di documenti informatici da Pubbliche Amministrazioni.
Al fine di formare documenti informatici web in forma propedeutica alla conservazione, sarà rivolto lo sforzo del legislatore e dei gruppi di lavoro delle entità, che attorno ad esso orbitano.
Il documento informatico sul web
Di fatto la formazione di documenti informatici sul web riferendosi al DPCM 13/11/2014 , avviene in due modalità : la prima (art.3 comma 1 lett.a) tramite l’utilizzo di appositi strumenti software, ove al termine della formazione i medesimi vengono pubblicati sul web; la seconda (art.3 comma 1 lett.d) tramite la generazione o raggruppamento, anche in via automatica, di un insieme di dati o registrazioni, provenienti da una o piu’ basi dati, anche appartenenti a piu’ soggetti interoperanti, secondo una struttura logica predeterminata e memorizzata in forma statica. Il web come oggi è conosciuto rispecchia principalmente la seconda, con alcune specificità che ricadono nella prima.
“Assioma 1 : Un sito web è principalmente un insieme di documenti informatici formati secondo l’art.3 comma 1 lett.d del DPCM 13/11/2014 e come tale va trattato”
L’assioma è inteso come punto di partenza della trattazione che si andrà sviluppando e non come verità assoluta; nella forma più generale possibile un sito web rientra nella categoria di “Documento interattivo dinamico” secondo le definizioni correnti in materia. L’assioma ha validità laddove si intenda lo scopo della conservazione come la “capacità di ri-creare, o ri-eseguire l’entità in questione” e che implica che “l’autore/produttore sia un partecipante attivo nella conservazione”.
• L’autenticità della risorsa è assicurata dal coinvolgimento dell’autore/produttore nella creazione di un surrogato che riflette le sue intenzioni
• La natura di documento è garantita dal fatto che l’autore/produttore produce il surrogato nel corso ordinario delle sue attività e per gli scopi della sua attività”
L’utilizzo di standard è la base di partenza per raggiungere lo scopo di ri-creare l’entità conservata, così come la minimizzazione delle fonti dinamiche esterne al sito, mentre più facili da trattare sono i dinamismi derivanti dall’uso di basi dati del produttore o i link a risorse esterne persistenti.
Per le argomentazioni di cui sopra, una rappresentazione di documento informatico idonea alla trattazione di cui all’assioma 1 è il WARC . Il formato WARC ( Web Archive ) specifica un metodo per combinare più risorse digitali in un file di archivio aggregato con le relative informazioni . Le risorse sono datate, identificate da URI e precedute da semplici intestazioni di testo. Per convenzione i file di questo formato hanno estensione ” .warc ” e tipo MIME “application/warc”.
Il formato di file WARC è una revisione/generalizzazione del formato ARC utilizzato da Internet Archive per archiviare blocchi di informazioni raccolte dai crawler web, durante la fase di ‘harvesting’.
Tale formato, essendo un contenitore anche di altre risorse non è garante della leggibilità nel tempo delle singole risorse in esso contenute; valgono pertanto le stesse implicazioni che si affrontano quando viene trattato un documento informatico in formato RFC 2822/MIME (Mail).
WARC in Action
Esistono diversi strumenti di web-crawling e di rappresentazione delle informazioni archiviate, purtroppo la veloce evoluzione delle nuove tecnologie rende molto complessa la sfida di riuscire a ricreare con esattezza l’entità conservata.
Nell’esempio viene riportato il sito http://opencantieri.mit.gov.it/ alla data del 29/12/2015 realizzato secondo le specifiche di design (in stadio alfa) proposte su http://design.italia.it ; nelle due immagini si osserva ciò che è rappresentato all’utente, nel caso di accesso ‘reale’ al sito e cosa vede l’utente da una rappresentazione del medesimo dal WARC estratto (tratto da http://web.archive.org Wayback Machine )
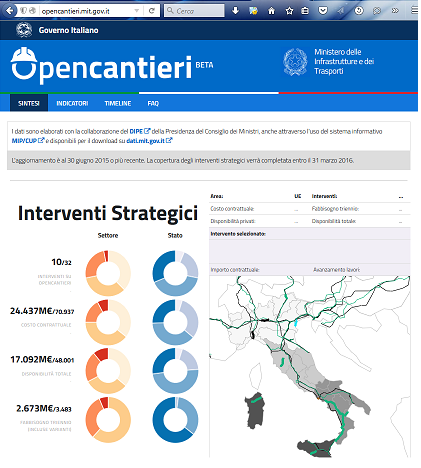 Versione originale
|
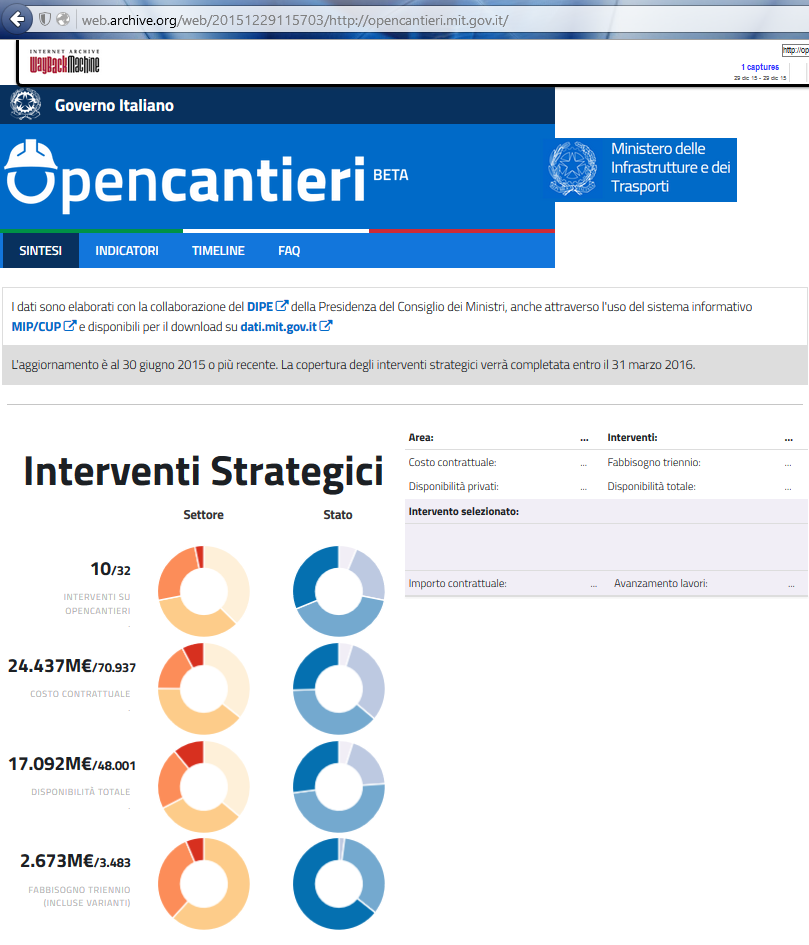 Versione riproposta via web.archive.org
|
Si nota che non tutti gli elementi sono stati riproposti correttamente. Vediamo ora quali sono gli elementi, in dettaglio che compongono la singola risorsa “home page di open cantieri”:
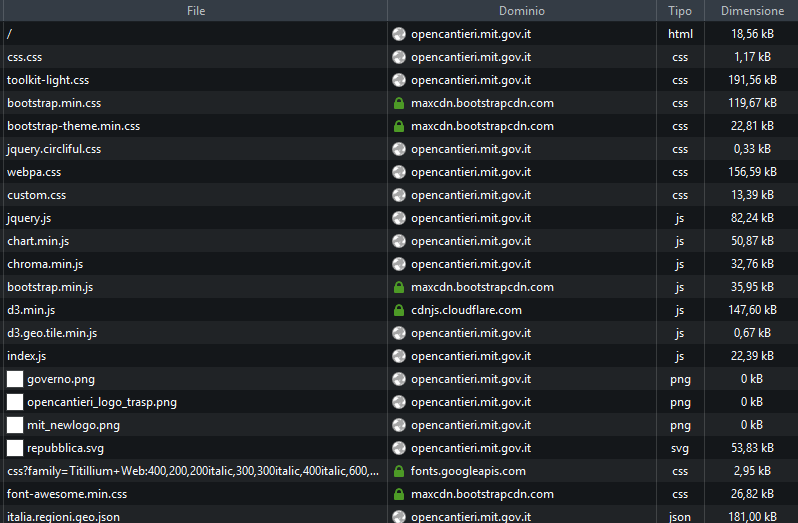
Elementi che compongono la home page di http://opencantieri.mit.gov.it/
Trattasi di un html principale, diversi css, alcune immagini png , una svg, diverse librerie javascript (js) ed un pacchetto dati json (italia.regioni.geo.json). Alcuni elementi vengono forniti da server differenti da quello principale ( maxcdn.bootstrapcdn.com , cdnjs.cloudflare.com … ).
Il WARC generato deve contenere TUTTI gli elementi che hanno portato alla composizione della pagina. Estraendolo con il servizio https://webrecorder.io/ ed esaminandolo con uno strumento opportuno, osserviamo che in esso tutti gli elementi evidenziati nella figura sono presenti come elementi dell’archivio.
WARC-Target-URI: https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.6/d3.min.js
WARC-Target-URI: http://opencantieri.mit.gov.it/js/chart.min.js
WARC-Target-URI: http://opencantieri.mit.gov.it/img/repubblica.svg
WARC-Target-URI: http://opencantieri.mit.gov.it/img/opencantieri_logo_trasp.png
WARC-Target-URI: http://opencantieri.mit.gov.it/img/mit_newlogo.png
WARC-Target-URI: http://opencantieri.mit.gov.it/img/governo.png
WARC-Target-URI: http://opencantieri.mit.gov.it/data/italia.regioni.geo.json
WARC-Target-URI: http://opencantieri.mit.gov.it/css/webpa.css
WARC-Target-URI: http://opencantieri.mit.gov.it/css/toolkit-light.css
…
L’ottenimento di tutti gli elementi necessari alla corretta visualizzazione è l’obiettivo minimale da raggiungere; così facendo, con l’ausilio di un visualizzatore del WARC che ri-crei l’entità nel modo più verosimile possibile, viene di fatto realizzata la conservazione della risorsa.
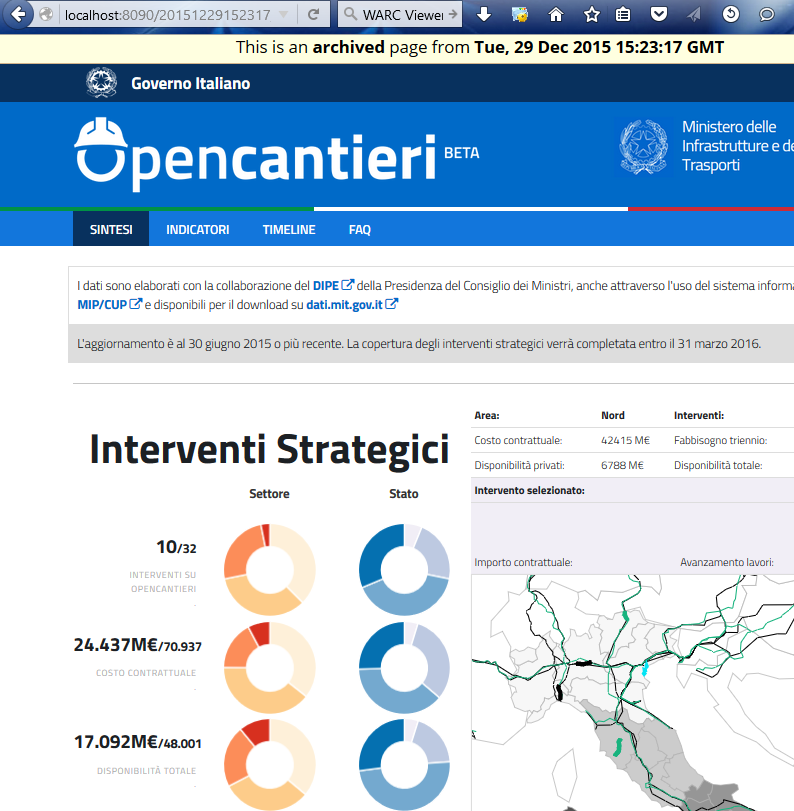
Versione visualizzata dal WARC con Web Archive Player 1.2.0 (pywb 0.10.9.1)
Nell’immagine si vede come la risultanza ottenuta con il viewer Web Archive Player sia decisamente congruente con la versione d’origine, animazioni ed effetti javascript compresi, giacchè tutti gli elementi che compongono la risorsa vengono forniti al browser web in maniera equivalente alla situazione originale. In particolare nella pagina in oggetto, sono stati trasferiti anche i dati necessari (in formato json) per il disegno della mappa e la gestione dell’interattività della stessa; infatti se sulla pagina ricostruita viene selezionata un elemento nella mappa, vengono riportati per esso i dati relativi.

Esempio di interazione con pagina visualizzata dal WARC
Questa è una situazione ideale, ove la risorsa web non necessita di ulteriori interazioni/elementi con la parte server-side per garantire il proprio funzionamento, se non quelle che vengono richieste inizialmente al caricamento della pagina. Purtroppo non è sempre così, in quanto vi sono risorse web ove il colloquio con il server è frequente e non prevedibile, perché frutto delle interazioni che l’utente ha con la risorsa web.
In generale, si fa una distinzione tra ‘Surface Web’ (o Web di Superficie) e ‘Deep Web’ (o Web Sommerso) , in sintesi si afferma che il ‘Surface Web’ è ciò che si riesce ad indicizzare, mentre il ‘Deep Web’ è composto da tutto ciò che non è possibile indicizzare.
Ad esempio :
-
risorse dinamiche: pagine web dinamiche, il cui contenuto viene generato sul momento dal server, che possono essere richiamati solo compilando un form o a risposta di una particolare richiesta (che citavamo prima);
-
risorse non linkate da altre: pagine Web che non sono collegate a nessun’altra pagina Web.
-
risorse ad accesso ristretto: siti che richiedono una registrazione o comunque limitano l’accesso alle loro pagine impedendo che i motori di ricerca possano accedervi;
…
Le risorse del ‘Web Sommerso’, nonostante i passi avanti compiuti dai crawler , ad oggi non risultano essere idonee alla conservazione, così da poterle ri-creare e ri-eseguire fedelmente.
“Assioma 2 : Una risorsa web conservabile a lungo termine, identificata univocamente da un URI (RFC 3986) e da un timestamp (RFC 3339 – ISO 8601), deve poter essere rappresentata in tutte le sue componenti, in modo da poter essere ri-creata e ri-eseguita in maniera equivalente all’originale ”
“Assioma 3 : Una risorsa web di cui all’assioma 2 è un documento informatico che assume la caratteristica di immodificabilità secondo l’art.3 comma 2 del DPCM 13/11/2014”
Conclusione : “Se una risorsa web rappresenta atti, fatti o dati giuridicamente rilevanti, la stessa deve essere conservata, pertanto deve avere le caratteristiche di cui all’assioma 2”
[1] Brewster Kahle è un ingegnere informatico americano, attivista di Internet , sostenitore di un accesso universale a tutta la conoscenza e bibliotecario digitale.Egli è il fondatore di Internet Archive , Internet Archive Federal Credit Union, Alexa e Thinking Machines e membro della Internet Hall of Fame.
[2] DECRETO DEL PRESIDENTE DEL CONSIGLIO DEI MINISTRI 13 novembre 2014 – Regole tecniche in materia di formazione, trasmissione, copia, duplicazione, riproduzione e validazione temporale dei documenti informatici nonche’ di formazione e conservazione dei documenti informatici delle pubbliche amministrazioni ai sensi degli articoli 20, 22, 23-bis, 23-ter, 40, comma 1, 41, e 71, comma 1, del Codice dell’amministrazione digitale di cui al decreto legislativo n. 82 del 2005. (15A00107) (GU Serie Generale n.8 del 12-1-2015)
[3] InterPARES Project – Il documento digitale – Cosa conserveremo in futuro? – 2008 – Dr Luciana Duranti – Project Director
[4] Dall’ allegato 2 – DPCM 13/11/2014 – Sez.5.8 Formati Messaggi di posta elettronica
Ai fini della conservazione, per preservare l’autenticità dei messaggi di posta elettronica, lo
standard a cui fare riferimento è RFC 2822/MIME. Per quanto concerne il formato degli allegati al messaggio, valgono le indicazioni di cui ai precedenti paragrafi. (Ovvero le caratteristiche di Apertura, Sicurezza, Portabilità, Funzionalità, Supporto allo Sviluppo e Diffusione)
[5] La Wayback Machine è un archivio digitale del World Wide Web e altre informazioni su Internet creato da Internet Archive . E ‘stato istituito da Brewster Kahle e Bruce Gilliat , ed è mantenuto con contenuti provenienti da Alexa . Il servizio consente agli utenti di visualizzare le versioni archiviate di pagine web attraverso il tempo , che l’archivio chiama un ” indice di tre dimensioni . “
[7] CSS – (Cascading Style Sheets, in italiano fogli di stile) – www.w3.org/TR/CSS
[8] PNG (Portable Network Graphics) – RFC 2083
[9] SVG (Scalable Vector Graphics) – http://www.w3.org/Graphics/SVG
[10] JS – Javascript – Standard ECMA-262
[11] JSON, acronimo di JavaScript Object Notation, è un formato adatto all’interscambio di dati fra applicazioni client-server – RFC 4627
[12] Il software vero e proprio dedicato alla fase di ‘Harvest’ delle risorse web e che nella nostra trattazione porta partendo da un URI (RFC 3986) specifico alla creazione del rispetto WARC che fotografa la risorsa al momento dell’harvest della stessa. Es. Heritrix
[13] Memorizzato in un sistema di gestione informatica dei documenti o di conservazione la cui tenuta puo’ anche essere delegata a terzi (art.3 comma 3del DPCM 13/11/2014)